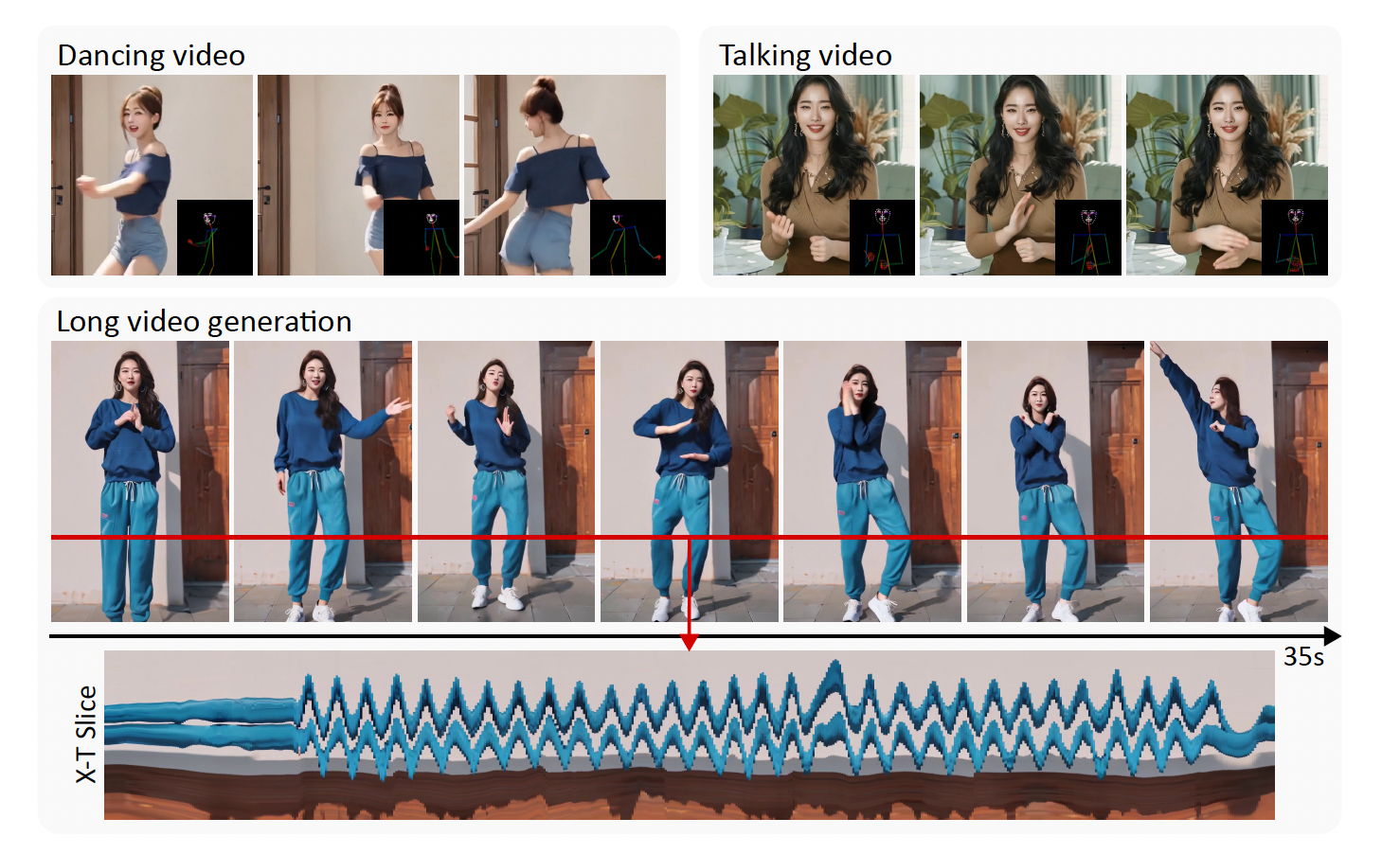
✨MimicMotion : 주어진 input image가 driving video의 motion을 따라하도록 변환된 video로 만들어준다는 의미이다.✨
Zhang, Yuang, et al. "MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance." arXiv preprint arXiv:2406.19680 (2024) [paper]
Abstract
논문 제목에 나와있듯 고품질과 temporal smoothness를 보장하는 confidence-aware pose guidance라는 것을 제시하고, 이를 활용하여 regional loss amplification이라는 것을 한다. 마지막으로, long video를 smooth하게 생성하도록 돕는 progressive latent fusion 방식을 도입한다.
결국 video generation 중에서도 Sora와 같이 video chunk를 한 번에 생성하는 것이 아닌, text-to-image diffusion model을 각 frame에 대해 적용하여 영상을 만드는 방식은 temporal consistency가 떨어지는 문제가 있습니다.
Pose의 연속성 + better pose guidance를 달성하기 위한 두 가지 키워드와, 영상 자체의 consistency를 개선하는 세 번째 키워드에 집중하시면 좋습니다.
Introduction
Follow Your Pose, DreamPose -다음 포스트에서 다룰, DisCo, MagicDance, AnimateAnyone, MagicAnimate ... 과 같은 image-conditioned pose-guided video generator가 많이 있지만, 손 부분이 부자연스럽다던지 temporal smoothness를 개선하느라 blurred frames가 생기는 등의 문제가 많다.
따라서 다음 세 개의 모듈로 위와 같은 문제를 해결한다:
Confidence-aware pose guidance : Temporal consistency의 개선
Regional loss amplification : 손 부위의 정확성과 선명도 개선
Progressive latent fusion : 긴 영상에서도 smoothness 유지
Related Work
1) Diffusion models for image/video generation
결국 image level diffusion은 너무 비싸서 LDM이 핫한데, 그 중에서도 video generator에서 꽤 효율적이면서 off-the-shelf인 Stable Video Diffusion(SVD)를 활용한다.
2) Pose-guided human motion transfer
Overly dense guidance는, 특히 source와 target의 identity가 다를 경우, 신체 라인 등에 영향을 과도하게 줄 수가 있어 오히려 품질을 망칠 수도 있다. 따라서 MimicMotion은 off-the-shelf human pose detectors를 사용하여 과도한 정보을 피한다. 이런 과정에서 생기는 inaccurate pose estimation의 영향은 Confidence-aware pose guidance가 막아준다.
3) Long video generation
몇 초짜리만 만드는 것은 응용성이 떨어진다. Autoregressive methods는 길게는 만들 수 있겠지만, 당연히 품질이 저하되고 long-term temporal coherence가 떨어진다. Hierarchical approach는 global diffusion model로 coarse storyline만 잡아놓고, local diffusion models로 iterative하게 비디오를 정제해낸다. MultiDiffusion에서 spatial continuity를 신경 쓴 Lumiere라는 모델도 있지만, MimicMotion은 temporal continuity를 신경 쓰는 방식으로 MultiDiffusion을 확장하는 것으로부터 아이디어를 얻어 progressive latent fusion을 제안한다.
VideoLDM과 같이 text-to-image model에 spatial layer를 끼워넣은 후 temporal axis에 대해서도 학습(예를 들어 3D convolution을 통해)하도록 fine-tune하면 짧은 video를 생성할 순 있지만 당연히 batch size(= video length)가 커질 수록 효과는 줄어들게 됩니다.
Method
Data Preparation
Training set을 구성해야 한다. Triplet이 필요한데, 1) reference image, 2) video frames 그리고 3) pose.
주어진 video에서, 일정 간격으로 정해진 숫자의 frames가 sampling되어 2)를 얻는다. 3) 은 필요한 frame에 DWPose를 사용해서 추출할 수 있다.
1)도 2)와 같이 똑같이 주어진 video에서 같은 방식으로 무작위로 sampling된다.
왜냐하면 inference를 할 때는 reference image와 driving pose video의 subject가 다르겠지만, training을 할 때는 source가 하나밖에 없으니 self-referencing을 해야하므로 같은 subject더라도 같은 비디오에서 무작위 추출을 하는 것입니다.
*이 부분을 먼저 보면 헷갈릴 수가 있어서, architecture 설명을 본 뒤에 revisit하길 추천드립니다.
Pose-guided Video Diffusion Model
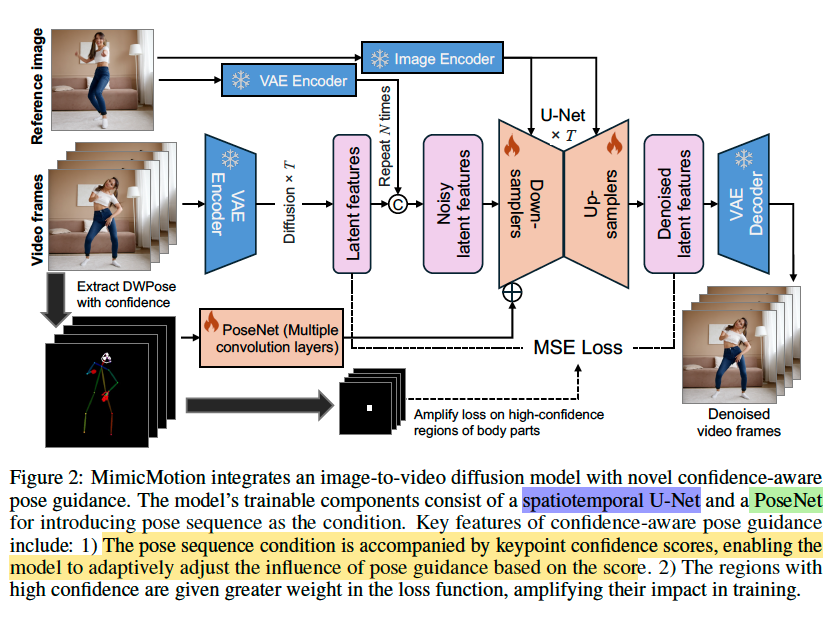
VAE encoder : 각 video frame/sampled reference image에 대해서 독립적으로 적용된다 - temporal or cross-frame interaction을 고려하지 않고.
VAE decoder : 여기에서 spatiotemporal interaction을 할 수 있도록 temporal layers를 끼워넣는다.
PoseNet : DWPose를 통해 추출한 pose를 latent representation으로 만들어주는 그냥 convolutional layers다. 이것 대신 위의 VAE encoder는 pose representation domain에 대해서 학습된 것이 아니기 때문에 당연히 사용할 수 없다.
이제 conditioned image generation이 어떻게 이루어지는지 보자.
1) Reference image : 1. VAE encoder를 거친 output이, U-Net의 input latent에 더해지고 2. CLIP을 거쳐 U-Net에 cross-attention을 통해서도 주입된다.
2) Pose : PoseNet을 거친 output이, U-Net의 convolution의 output에 element-wise로 더해진다 > spatial dimension이 보존된다.
*1.1) : Conditioning이 한 개인 경우 U-Net에 cross-attention으로 들어가는 것이 일반적이지만, 두 개인 경우 한 쪽이 spatial dimension이 U-Net의 input latent와 맞을 때 두 개를 channel-wise로 concatenation하는 방식이 InstructPix2Pix 논문에서 소개되고 있으니 참고해보시길 바랍니다.
또 논문에서 모든 U-Net block에 대해서 1.2)를 진행하지 않았는데 그에 대한 이유도 설명하고 있습니다.
Confidence-aware pose guidance & Hand region enhancement
위에서 말했듯이 DWPose를 off-the-shelf로 가져오면서 정확도에는 저하가 있었는데, pose-guidance이기 때문에 pose estimation 자체가 부정확하다면 프레임끼리의 motion consistency가 이상해지면서 전반적인 temporal smoothness가 떨어져보이게 된다.
그래서 MimicMotion은 pose guidance frame의 brightness를 pose estimation의 confidence level로 간주한다. 이 confidence scores로 pose와 keypoints를 그릴 색을 결정한다면, re-weighted pose guidance map과 같은 효과를 누리게 된다.
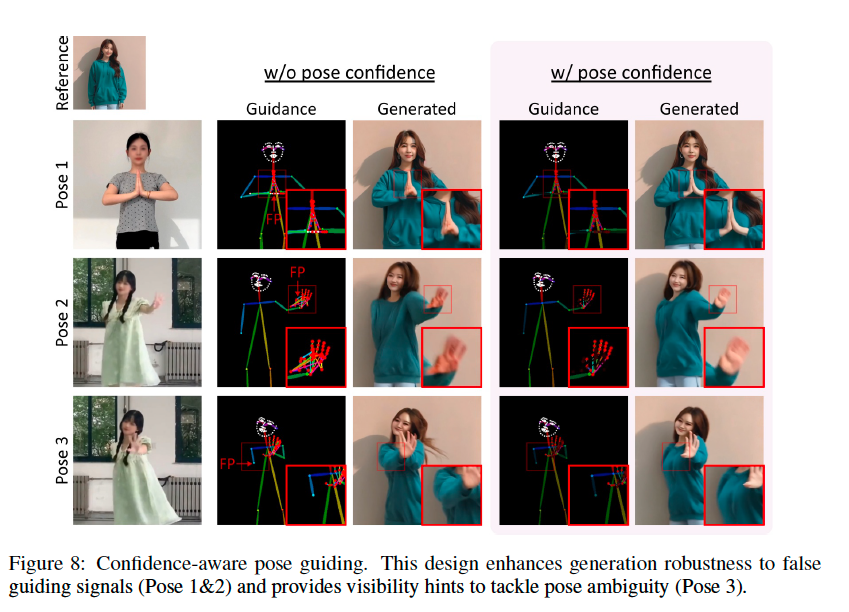
여기서 그냥 넘어가지 않고, "pose는 PoseNet을 거친 output이, U-Net의 convolution의 output에 element-wise로 더해진다"는 사실과 연결하여 attention map과 같은 효과를 가지게 됨을 유추할 수 있습니다.
그렇다면 threshold를 설정하여 confidence score를 기반으로 region에 대한 reliability를 따질 수 있게 되고, threshold보다 낮은 region은 masking하여 loss 계산 시에 unmasked region을 특정 값만큼 amplify함으로써 reliable한 부위(e.g. blurry하지 않은 진짜 손 부분)에 대한 효과적인 training이 가능해진다.
Progresseive latent fusion for long video generation
위에서 MultiDiffusion으로부터 파생된 Lumiere와 달리 temporal continuity를 신경쓰는 방향으로 아이디어를 얻었다고 했다.
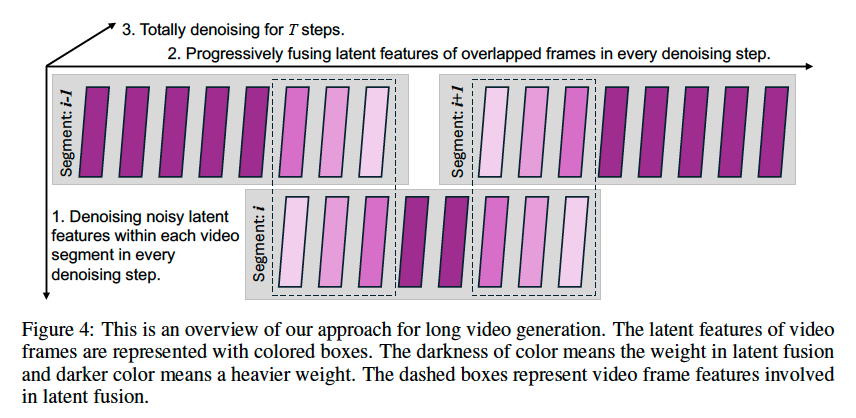
아이디어는 아주 간단하다.
0) 전체 frame sequence를 N개의 frames가 담긴 segments로 나눈다. 이 때 서로 C개의 frames만큼 overlapped된다.
1) 각 video segment의 모든 frames - latent features -을 전부 denoise한다.
2) Ovelapped frames - latent features -를 fuse한다. 상대적인 위치에 따라 fusion weight가 정해지는데, 겹친 부분의 두 개의 연한 보라색 쌍이 합쳐져서 진한 색이 된다는 것이 직관적이다.
3) T step만큼 반복한다.

'Pose Guidance' 카테고리의 다른 글
| [논문 리뷰] Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation (0) | 2024.07.18 |
|---|